문제1
- 혈액형별로 그룹을 맺어, 키의 평균값을 확인
[1
blood
A 171.090909
AB 179.000000
B 165.875000
O 170.233333
Name: height, dtype: float64문제2
- 혈액형별로 그룹을 맺고, 성별로 또 그룹을 나눈 후 키의 평균값을 확인1
blood gender
A 남자 179.000
여자 164.500
AB 남자 179.000
B 여자 165.875
O 남자 179.000
여자 165.850
Name: height, dtype: float64
10. 중복값 제거하기
df['blood']
0 A
1 A
2 A
3 O
4 AB
5 NaN
6 O
7 A
8 B
9 A
10 A
11 B
12 A
13 A
14 B
15 B
16 A
17 A
18 A
19 O
20 A
Name: blood, dtype: object
# drop_duplicates(): 중복된 데이터를 제거
df['blood'].drop_duplicates() # 중복 제거 후 가장 먼저 나온 인덱스가 나옴
0 A
3 O
4 AB
5 NaN
8 B
Name: blood, dtype: objectdf['blood'].drop_duplicates(keep='last')
4 AB
5 NaN
15 B
19 O
20 A
Name: blood, dtype: object
# value_counts(): 열의 각 값에 대한 데이터의 개수를 반환. NaN은 생략
df['blood'].value_counts()
blood
A 12
B 4
O 3
AB 1
Name: count, dtype: int64df['company'].value_counts()
company
빅히트 7
어도어 5
와이지 4
에스엠 2
판타지오 1
애플 1
Name: count, dtype: int64df['company'].value_counts(dropna=False) # NaN 1 표시
company
빅히트 7
어도어 5
와이지 4
에스엠 2
판타지오 1
NaN 1
애플 1
Name: count, dtype: int64
11. 데이터프레임 합치기
df1
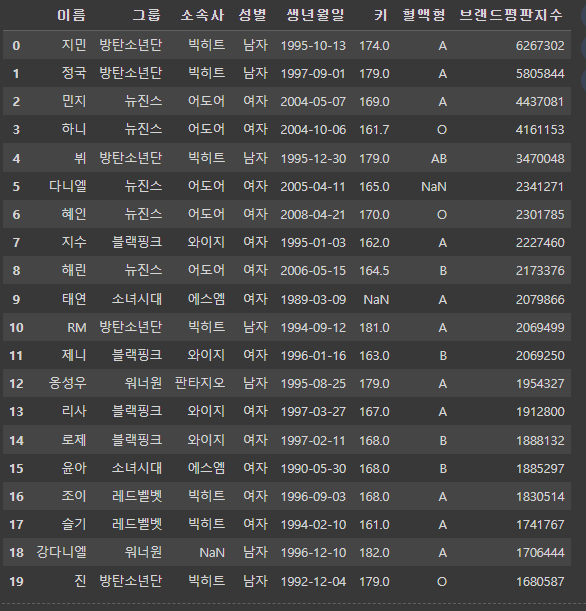
df2
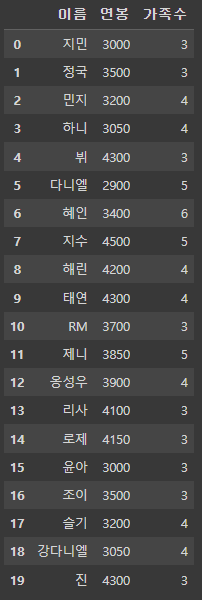
df_copy = df1.copy()
pd.concat([df1, df_copy])
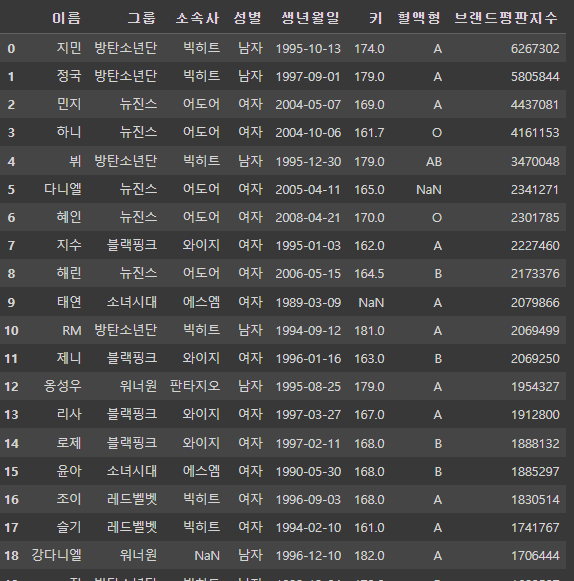
df_concat = pd.concat([df1, df_copy])
# reset_index(): index를 새롭게 적용
# drop=True 옵션을 사용하여 기준 index가 컬럼으로 만들어지는 것을 방지
df_concat.reset_index()
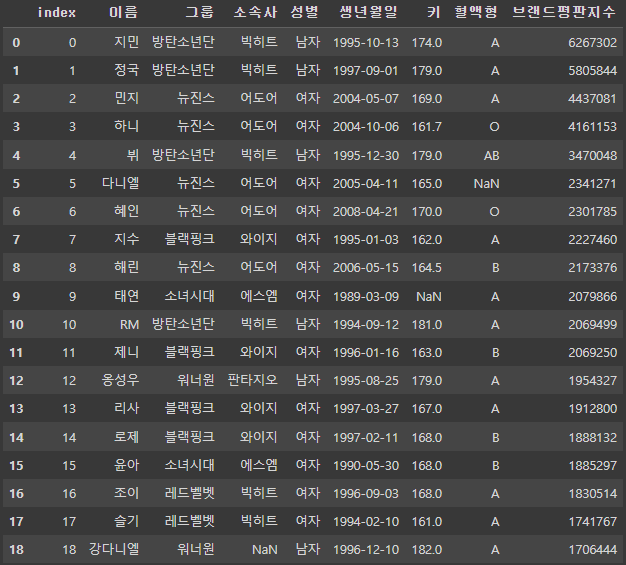
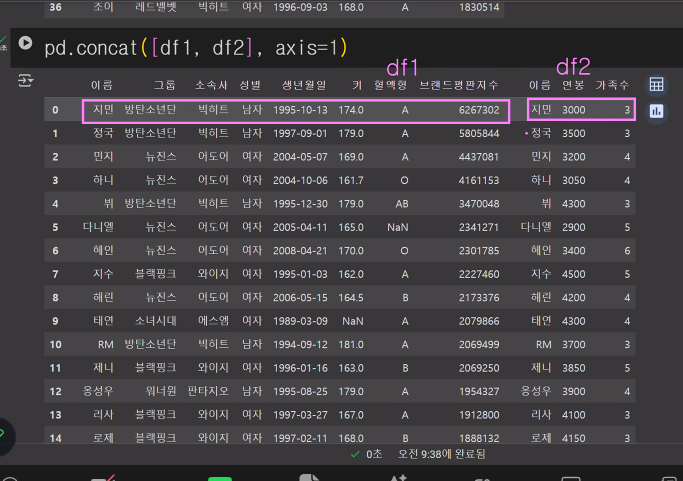
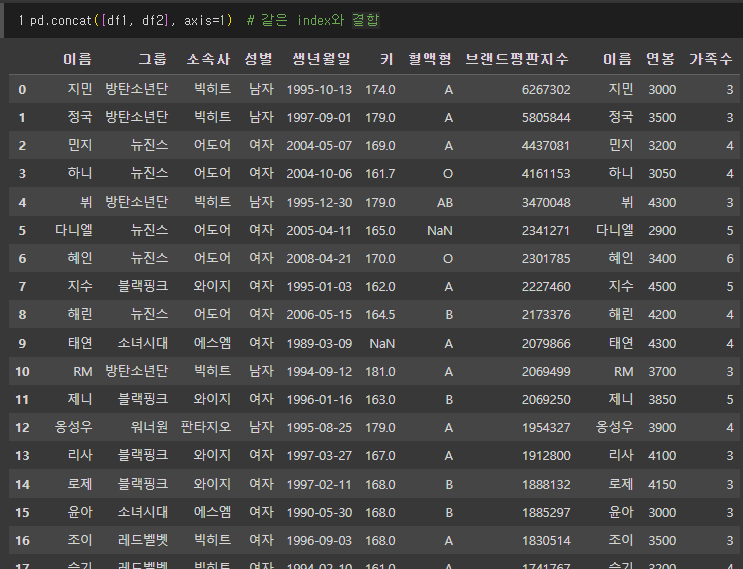
pd.concat([df1, df2], axis=1) # 같은 index와 결합
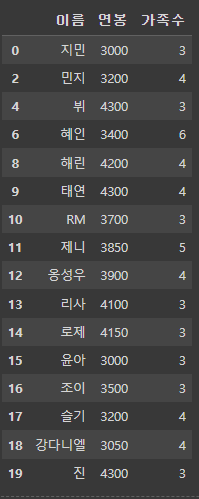
df3 = df2.drop([1, 3, 5, 7])
df3
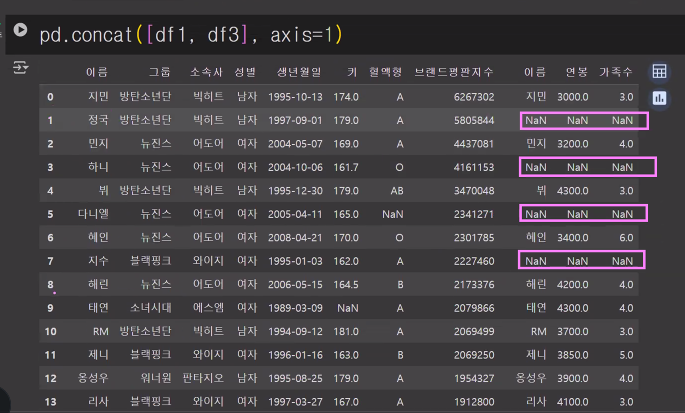
pd.concat([df1, df3], axis=1)
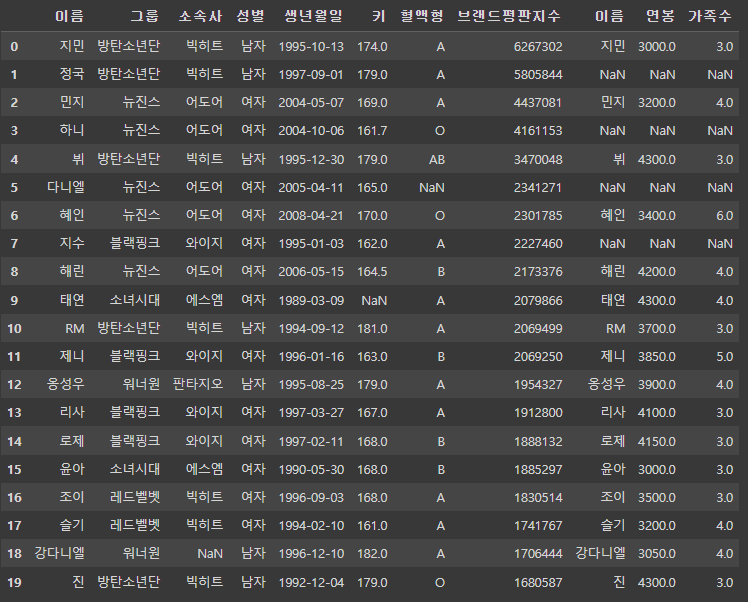
df_right = df2.drop([1, 3, 5, 7, 9], axis=0)
df_right # 데이터 1, 3, 5, 7, 9 없음
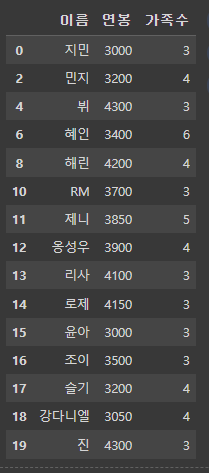
df_right = df_right.reset_index(drop=True)
df_right # 빈 구멍없이 index가 리셋
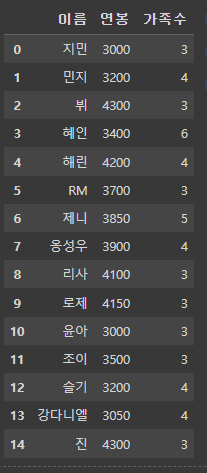
pd.concat([df1, df_right], axis=1) # 인덱스 기준으로 합쳐져서 이상하게됨
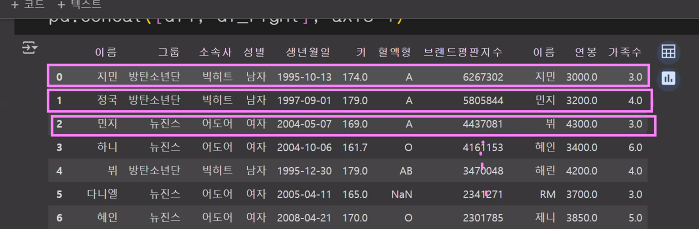
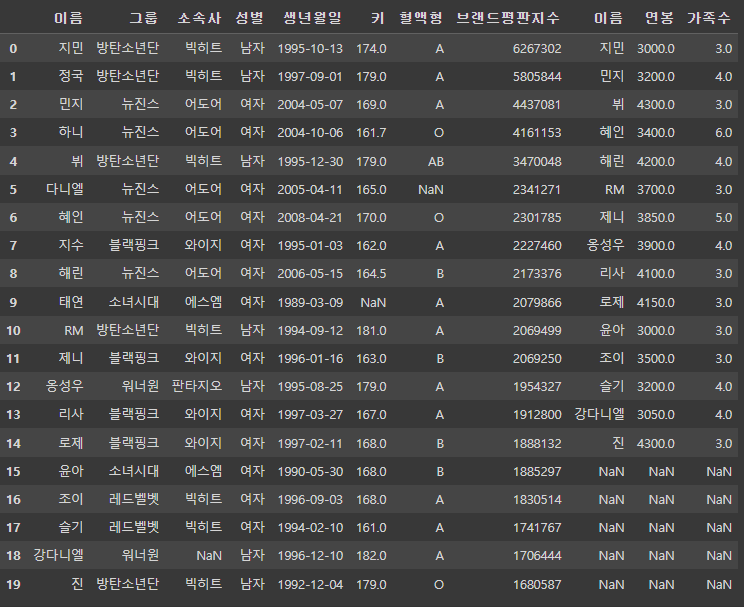
# merge(): 특정 고유한 키(unique, id)값을 기준으로 합침
# merge(데이터프레임1, 데이터프레임2, on='유니크값', how='병합의 기준')
# 병합의 기준: left, right, inner, cross
pd.merge(df1, df_right, on='이름', how='left') # 잘 합쳐짐
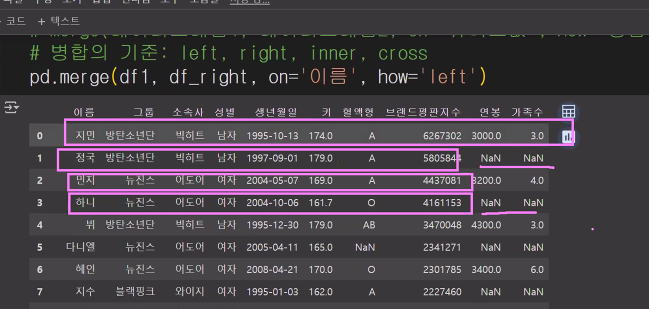
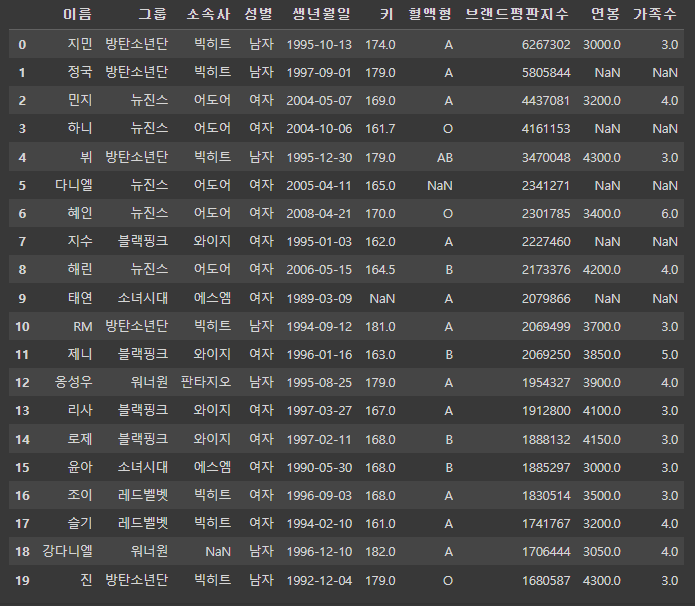
pd.merge(df1, df_right, on='이름', how='right') # 잘 합쳐짐 => 정국 하니 없어짐(1,3,5,7,9 사라짐)
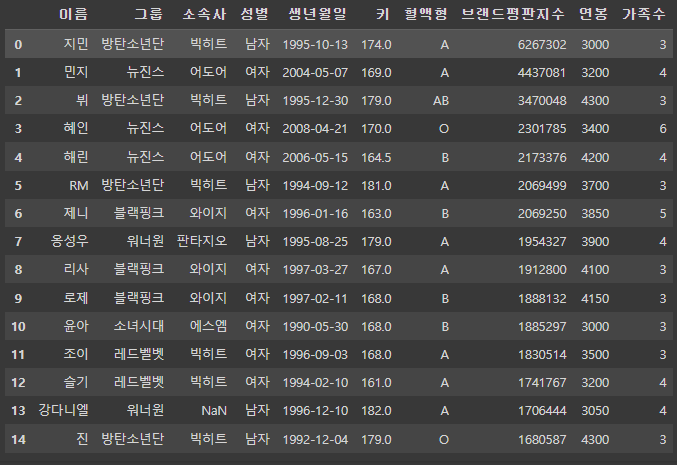
pd.merge(df1, df_right, on='이름', how='inner')
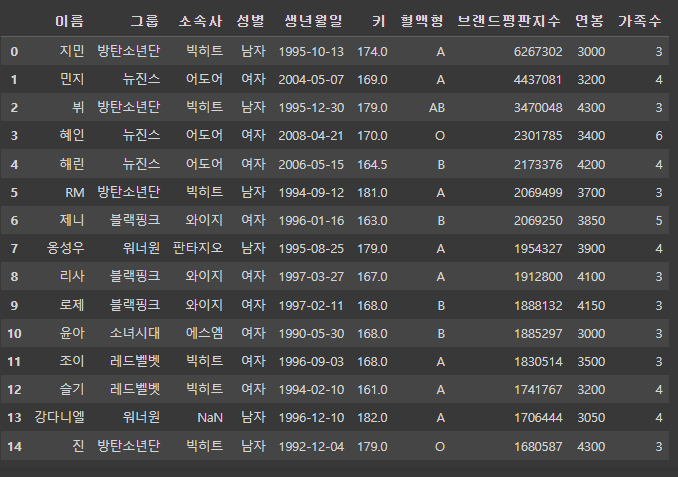
# pd.merge(df1, df_right, on='이름', how='cross' ) # 에러
pd.merge(df1, df_right, how='cross' ) # on='이름' 빼면 에러 안남
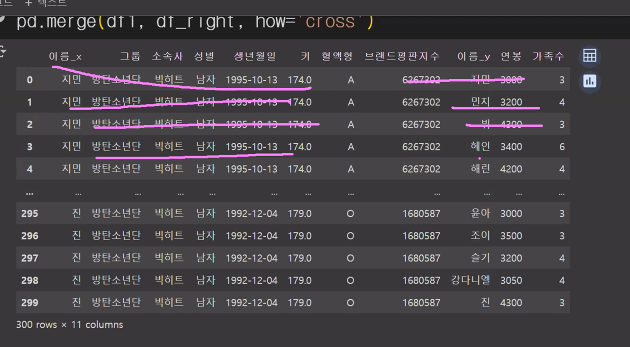
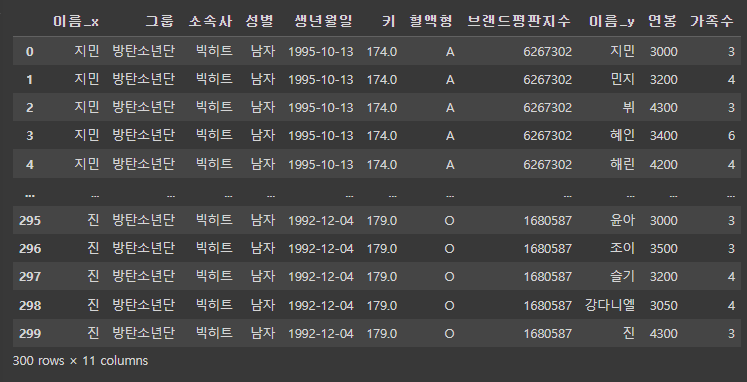
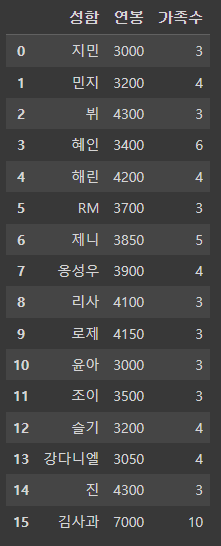
문제
- df_right 데이터프레임에 아래와 같은 데이터를 추가하고 df1과 merge하여 출력
- "이름: 김사과, 연봉:7000, 가족수:10"
- 단, how=right로 함

pd.merge(df1, df_right, how='right')
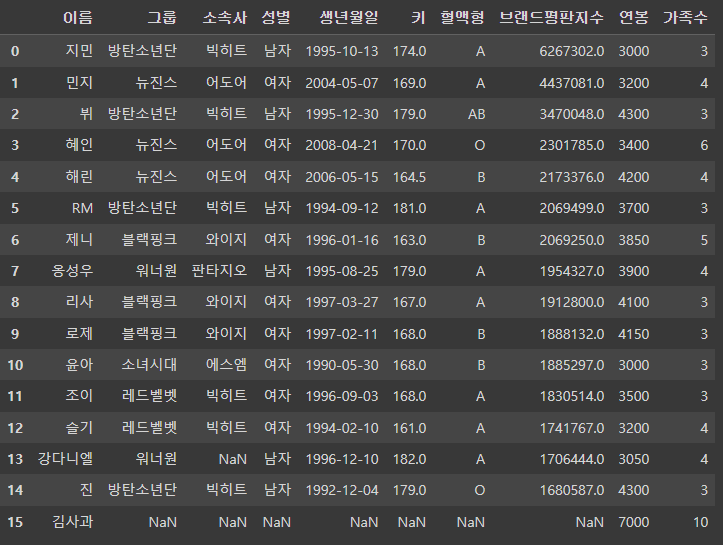
df_right.columns = ['성함', '연봉', '가족수']
df_right
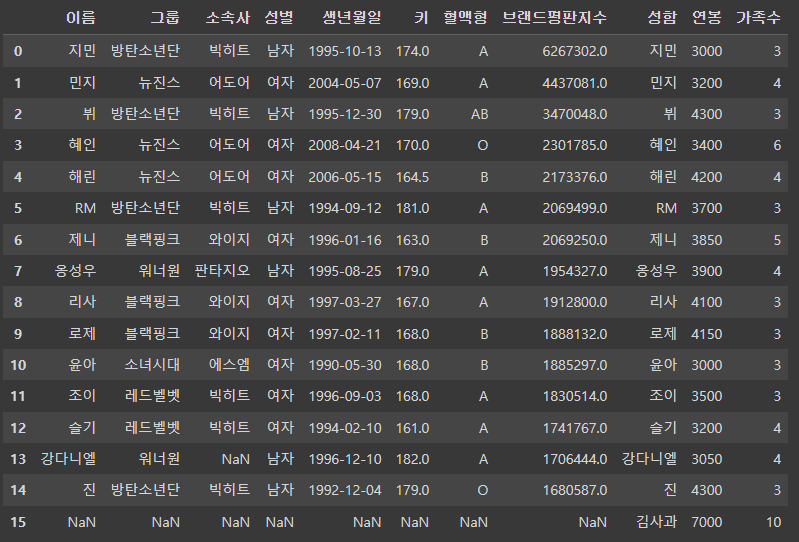
# pd.merge(df1, df_right, on='이름', how='right') # KeyError: '이름'=> 이름이 없어서 에러
pd.merge(df1, df_right, left_on='이름', right_on='성함', how='right')
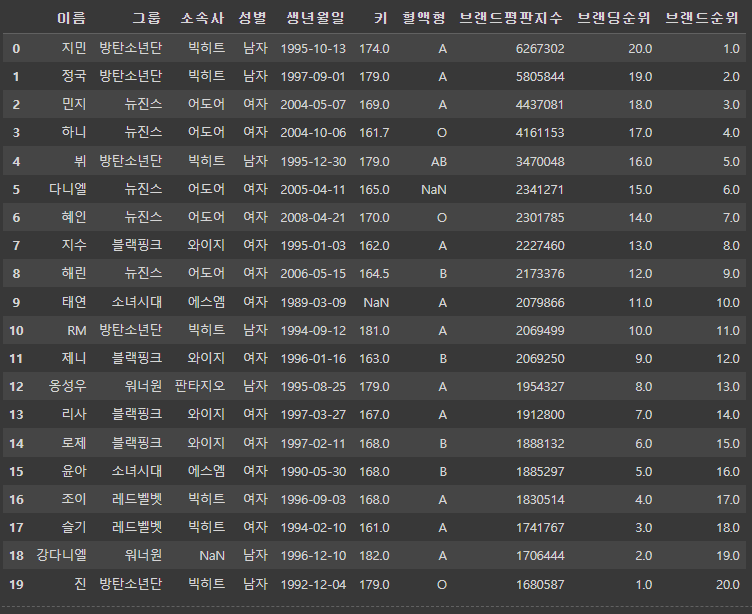
12. 등수 매기기
[15

df1['브랜드순위'] = df1['브랜드평판지수'].rank(ascending=False)
df1
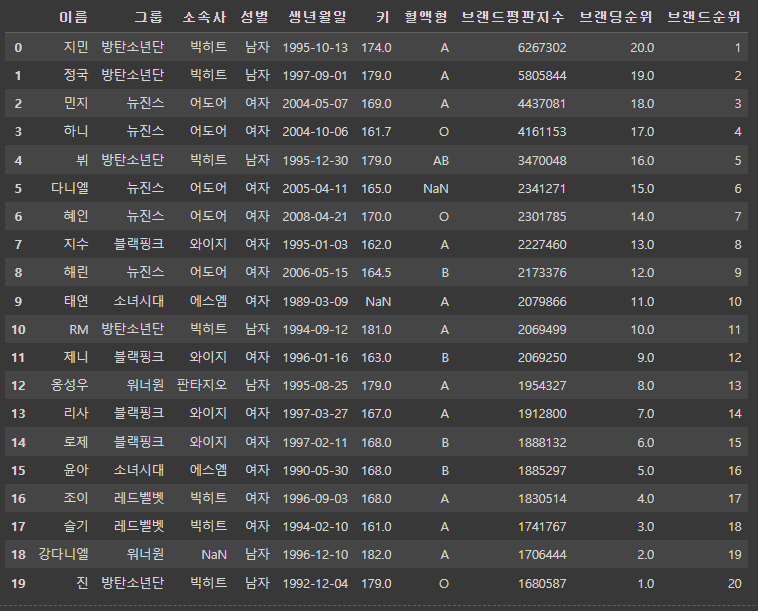
# 타입 바꾸기
# astype(): 특정열의 자료형을 변경
df1['브랜드순위'] = df1['브랜드순위'].astype(int)
df1
df1['브랜드순위'].dtypes

13. 날짜타입 사용하기
[

df['birthday']
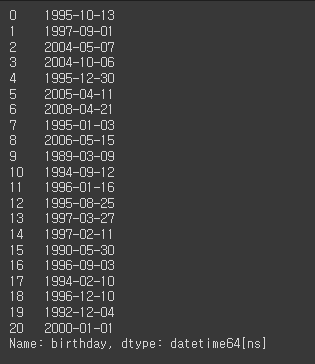
# to_datetime(): object타입에서 datetime타임으로 변환
df['birthday'] = pd.to_datetime(df['birthday'])
df['birthday']
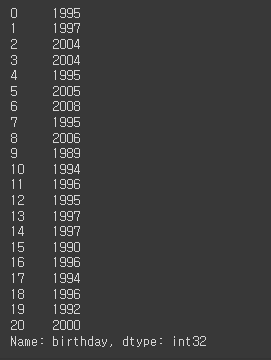
# 년도 year
df['birthday'].dt.year
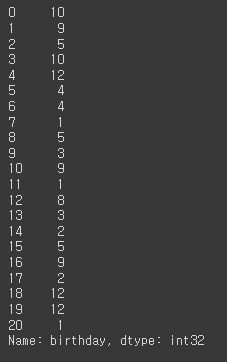
# 월 month
df['birthday'].dt.month
# 날짜 day
df['birthday'].dt.day
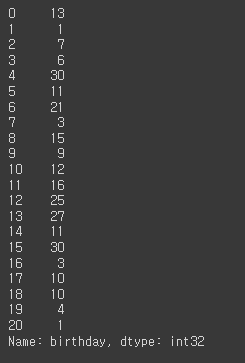
# 시간 hour
df['birthday'].dt.hour
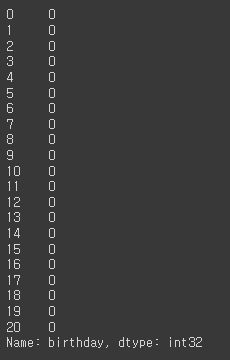
# 분 minute
df['birthday'].dt.minute
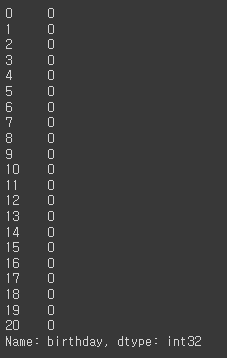
# 초 second
df['birthday'].dt.second
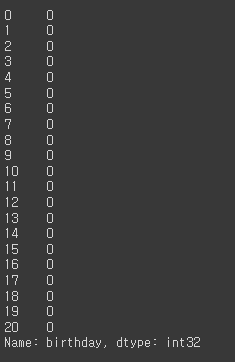
# 요일
df['birthday'].dt.dayofweek # 요일: 0(월요일) ~ 6(일요일)
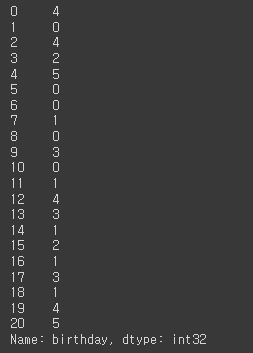
# 주
df['birthday'].dt.isocalendar().week # 일년중에 몇번째 주였는지

14. apply 사용하기
- Series나 DataFrame에 구체적인 로직을 적용하고 싶을 때 사용
- apply를 적용하기 위해서는 별도의 함수를 먼저 정의해야 함
- 작성된 함수를 apply 에 매개변수로 전달함
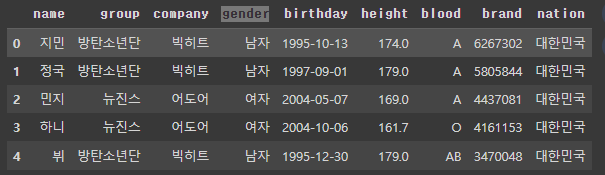
df.head()
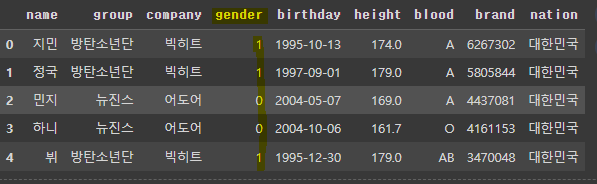
# 성별이 남자는 1, 여자는 0으로 변환(loc를 사용)
df.loc[df['gender'] == '남자', 'gender'] = 1
df.loc[df['gender'] == '여자', 'gender'] = 0
df.head()
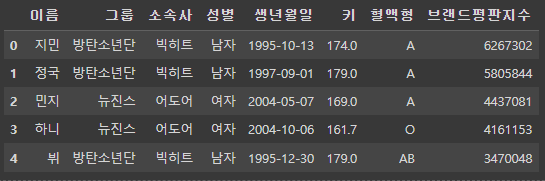
df = pd.read_csv('/content/drive/MyDrive/KDT/5. 데이터 분석/데이터/idol.csv')
df.head()
def male_or_female(x):
if x == '남자':
return 1
elif x == '여자':
return 0
else:
return None
df['성별'].apply(male_or_female)
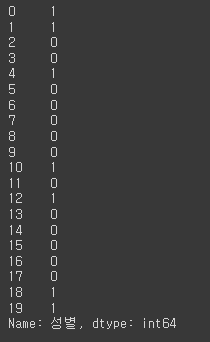
df['성별'].apply(lambda x: 1 if x == '남자' else 0)
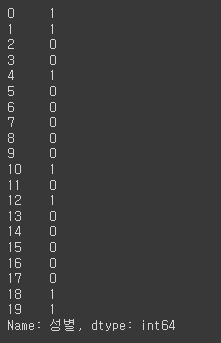
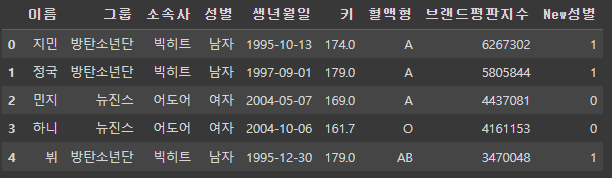
df['New성별'] = df['성별'].apply(lambda x: 1 if x == '남자' else 0)
df.head()
15. map사용하기
- 딕셔너리를 통해 데이터와 같은 키의 값을 적용
df = pd.read_csv('/content/drive/MyDrive/KDT/5. 데이터 분석/데이터/idol.csv')
df.head()
map_gender = {'남자': 1, '여자':0}
df['성별'].map(map_gender) # map이 자동을 바꿔줌
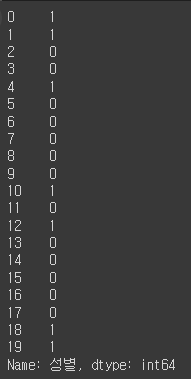
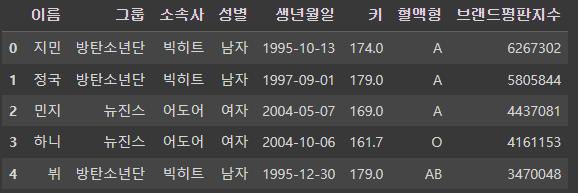
df['New성별'] = df['성별'].map(map_gender)
df.head()
16. 데이터프레임의 산술연산
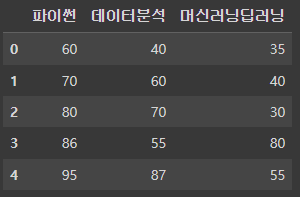
df = pd.DataFrame({
'파이썬':[60, 70, 80, 86, 95],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 80, 55]
})
df
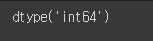
df['파이썬'].dtypes
type(df['파이썬']) # series
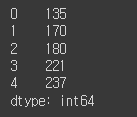
df['파이썬'] + df['데이터분석'] + df['머신러닝딥러닝']
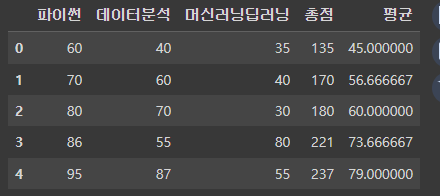
# df에 총점, 평균이라는 파생변수를 만들고 파생변수에 총점, 평균을 구해서 저장
df['총점'] = df['파이썬'] + df['데이터분석'] + df['머신러닝딥러닝']
df['평균'] = df['총점'] / 3
df
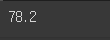
df['파이썬'].sum() # df['파이썬'].sum(axis=0) => 행끼리 더한거

df['파이썬'].mean() # 행끼리 평균
# 타입 다를때
df1 = pd.DataFrame({
'파이썬':[60, 70, 80, 86, 95],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 80, 55]
})
df2 = pd.DataFrame({
'파이썬':['C', 'A', 'B', 'B', 'A'],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 80, 55]
})
# df1 + df2 # 에러 => 일치하지 않아서 'int' and 'str'
df1 + 10
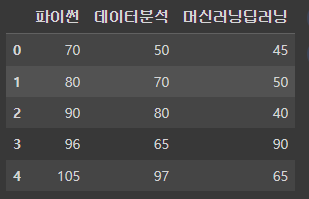
# df2 + 10 # 에러 => 문자열 있어서
# 갯수 다름
df1 = pd.DataFrame({
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 80, 55]
})
df2 = pd.DataFrame({
'데이터분석':[40, 60, 70, 55],
'머신러닝딥러닝':[35, 40, 30, 80]
})
# 행의 개수가 다를 경우 빠진 데이터를 NaN으로 취급하기 때문에 연산이 안됨
df1 + df2
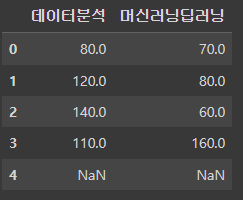
17. select_dtypes
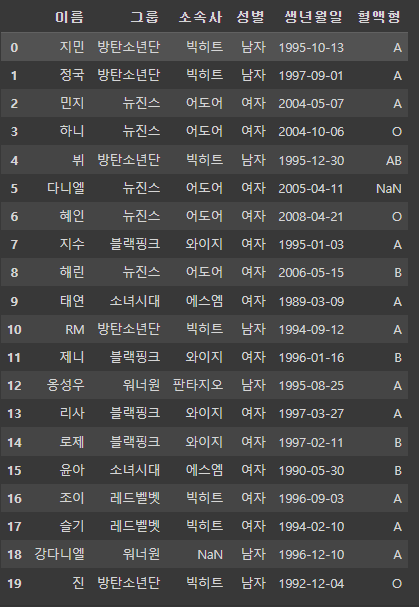
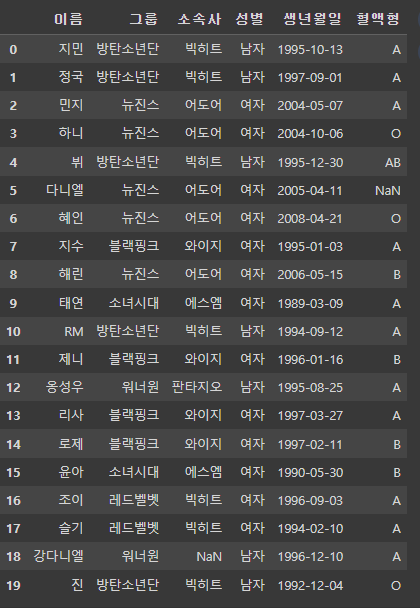
df = pd.read_csv('/content/drive/MyDrive/KDT/5. 데이터 분석/데이터/idol.csv')
df.head()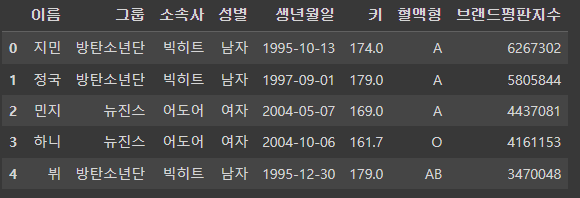
df.info()
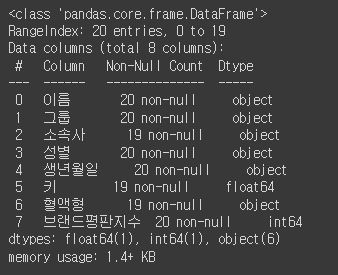
df.select_dtypes(include='object') # 문자열 컬럼만 가져오기
df.select_dtypes(exclude='object') # 문자열 컬럼만 빼고 가져오기
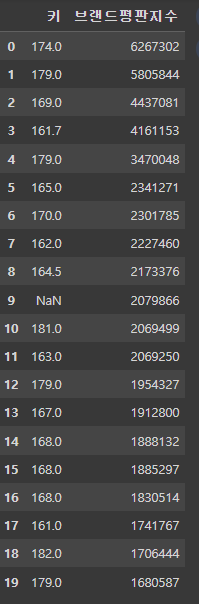
# 문자가 아닌 컬럼에만 10을 더함
df.select_dtypes(exclude='object') + 10
문제
- 문자열을 가지고 있는 컬럼의 이름만 저장하여 출력
str_cols = df.select_dtypes(include='object').columns
str_cols

df[str_cols]
18. 원 핫 인코딩(One Hot Encoding)
- 원 핫 인코딩은 한개의 요소는 1, 나머지 요소는 0으로 만들어 카테고리형을 표현하는 방법
- 예) df['혈액형']
- 머신러닝/딥러닝 알고리즘에 넣어 데이터를 예측하려고 한다면 라벨 인코딩을 하여 수치 데이터로 변환
- 컴퓨터는 값 들간의 관계를 스스로 형성하게 될 수 있음
- 만약 B형은 1, AB형이 2라는 값을 가지고 있다면 컴퓨터는 'B형 + AB형 = O형'라는 이상한 관계를 맺을 수 있음
- 별도의 column들을 형성해주고 1개의 column에는 1, 나머지 column에는 0으로 넣어줌으로 'A, B, AB, O'형의 관계는 서로 독립적이다 라는 카테고리로 표현하는 방식(원 핫 인코딩)
blood_map = {'A':0, 'B':1, 'AB':2, 'O':3}
df['혈액형_code'] = df['혈액형'].map(blood_map)
df.head()
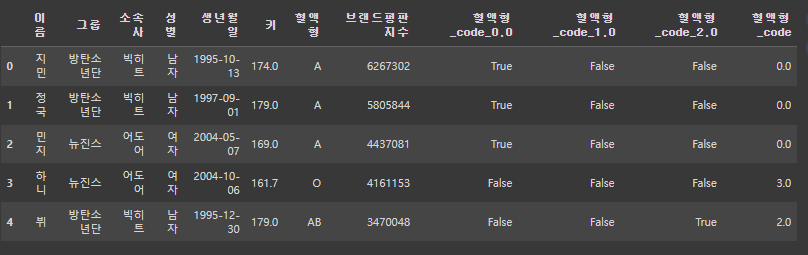
# get_dummies(): 원 핫 인코딩을 적용
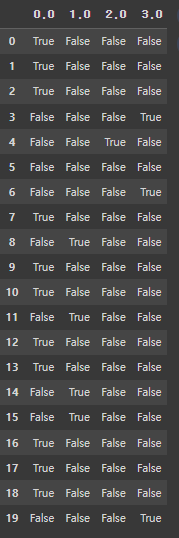
pd.get_dummies(df['혈액형_code'])
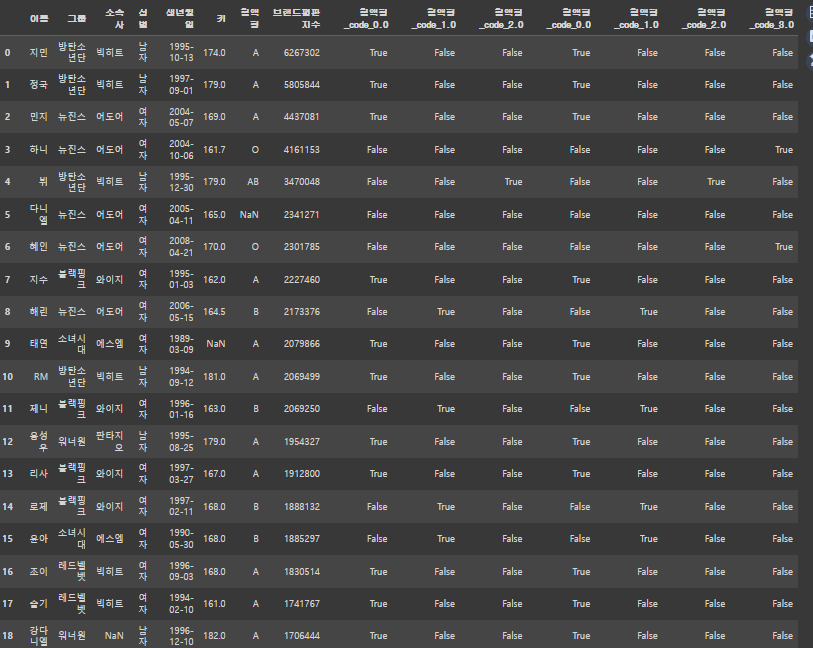
df = pd.get_dummies(df, columns=['혈액형_code'])
df
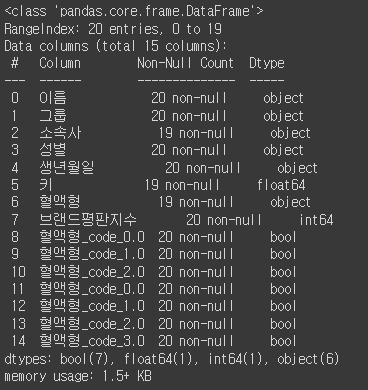
df.info()
'Python > 데이터분석' 카테고리의 다른 글
| 2024-05-28 상권별 업종 밀집 통계 데이터 (0) | 2024.05.30 |
|---|---|
| 2024-05-27 가상 온라인 쇼핑몰 데이터 (0) | 2024.05.27 |
| 2024-05-27 Matplotlib (0) | 2024.05.27 |
| 2024-05-23 판다스 (0) | 2024.05.23 |
| 2024-05-22 넘파이 (0) | 2024.05.22 |