https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
0. Abstract
- BERT: Bidirectional Encoder Representations from Transformers (트랜스포머의 양방향 인코더 표현)의 약자
- 모든 레이어에 양방향 문맥에서 공동으로 조절함으로써 라벨이 없는 텍스트로부터 깊은 양방향 표현들을 사전 훈련하도록 디자인 되었음
- Pre-training이기 때문에 마지막 layer만 수정함으로써 원하는 다양한 Task 적용이 가능하다.
- GLUE score to 80.5%로 이전 SOTA보다 7.7% 증가
1. Introduction
- BERT는 language representations (언어 표현)을 위한 모델이며, 따라서 먼저 이 language representations가 정확히 무엇인지를 이해하는 것이 필요함
- Pre-trained Language Representations은 크게 feature-based와 fine-tuning 두 가지 종류가 있음
- Feature-based (ELMo 등)
- Task-specific 한 모델을 따로 설계함
- 설계한 모델에서 pre-trained representation을 하나의 feature로 추가하여 학습
- Fine-tuning (GPT 등)
- 이는 위와 반대로 task-specific 한 모델을 따로 설계하지 않고, Task-specific 한 파라미터를 최소한으로 줄인 공통적인 모델을 사용
- 해당 모델로부터 task-specific 파라미터를 해당 테스크에 맞게 fine-tuning 시켜서 학습시킨다. 이 때의 테스크를 downstream task 라고 부름
- => 두 방식 모두 사용하는 목적 함수도 같고, 모델도 unidirectional (단방향) 언어 모델을 사용한다는 공통점이 있다.
- Feature-based (ELMo 등)
차이점
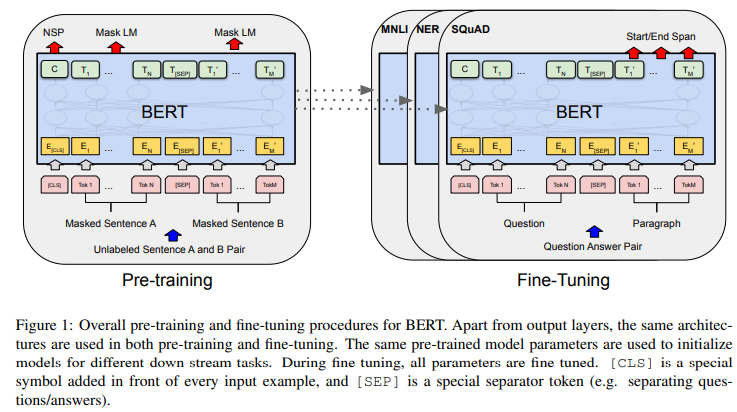
- BERT는 대용량의 unlabeled data로 pre-training 하고, 특정 task에 대해 transfer learning 하는 모델
- MLM(Masked Language Model)을 활용하여 이전 이후 정보를 모두 활용하여 Pre-training하는 bidirectional 학습 구조
- NSP(next sentence prediction) 학습 방법을 통해 문장 간의 연관성을 Pre-training 하도록 함
2. BERT : Model Architecture

- BERT는 transformer 중에서도 encoder 부분만을 사용
- BERT는 모델의 크기에 따라 base 모델과 large 모델을 제공
▶ Multi-layer bidirectional Transformer encoder
- L: number of layers (Transformer block)
- H: hidden size
- A: number of self attention heads
▶ BERTBASE
- L = 12, H = 768, A = 12
- Total parameters = 110M (1억1천만)
- Same model size as OpenAI GPT
▶ BERTLARGE
- L = 24, H = 1,024, A = 16
- Total parameters = 340M (3억4천만)
3. BERT: Input/Output representation
▶ sentence
- BERT에서 말하는 sentence는 영어 기준 S+V+O의 구조가 아님
- 연속적인 text span
- 우리가 알고 있는 문장이 아니어도 괜찮음
▶ sequence
- 이 논문에서 sequence가 하나의 입력 단위가 되는데, 이 값에는 그냥 하나의 문장이 들어올 수도 있고, 한 쌍의 문장이 합쳐져서 들어올 수도 있음
- 입력되는 문장에 언어적으로 말이 안되는 단어들을 나열한 값이 들어올 수도 있음
▶ token (토큰)
- 이 논문에서는 단어에 대한 토큰 임베딩으로 WordPiece1를 사용함
- 각 sequence의 첫 번째 토큰은 무조건 [CLS]로 시작하고, 문장 사이에는 [SEP]토큰을 삽입

▶ embedding (임베딩)
- 각 입력 임베딩에는 기본적으로 transformer 모델과 마찬가지로 토큰 임베딩과 positional 임베딩 진행
- 여러 문장을 합쳐서 sequence에 입력시키는 경우, 각 토큰마다 소속된 문장을 나타내는 학습된 임베딩도 추가하며 이를 segment embedding 이라고함
- 예를 들어서 첫 번째 문장은 0을 주고, 두 번째 문장은 1을 넣어서 구분하고, 하나의 문장만 사용할 경우 0으로 채울 수 있다
▶ BERT Input representation은 세가지의 합으로 구성됨
① Token embedding: WordPiece embeddings with a 30,000 token vocabulary
② Segment embedding
③ Position embedding: same as in the Transformer

4. Pre-training BERT Task #1: Masked Language Model (MLM)
- 전체 토큰 중 15%의 비율로 단어 중의 일부를 랜덤하게 [MASK] token 으로 변경



5. Pre-training BERT Task #2: Next Sentence Prediction (NSP)
- QA(Question Answering), NLI(Natural Language Inference) 등 많은 downstream task들이 두 문장사이의 관계를 학습시켜야 한다. 하지만 이러한 부분은 기존의 일반적인 언어 모델을 직접 적용할 수 없고, 해당 태스크마다 이러한 모델을 구현해야 했음
- BERT에서는 NSP 과정을 포함시키면서, 문장사이의 관계를 파악하는 모델도 같이 일반화시켰으며, 위의 bidirectional을 적용시킨 MLM은 기존의 transformer보다 그냥 성능적인 향상 정도였다면, NSP는 단순히 성능뿐만 아니라, 이 학습방법을 적용시키면서 모델 자체의 역할을 확장시켰다고 볼 수 있음
- 문장 관계를 학습시키기 위해서, 이 논문에서는 binarized NSP 태스크를 수행하고 Binarized NSP란, 학습에서 입력할 두 문장을 선택할 때, 50%는 바로 다음에 오는 문장을, 50%는 관련없는 문장을 선택해서 NSP에 사용한 것을 의미
- NSP는 매우 간단한 작업이지만, QA와 NLI에 매우 효과적으로 성능 향상이 있었음
6. Fine-tuning BERT
- batch size, learning rate, epoch이 다르며 dropout은 항상 0.1
- task에 따라 다르지만 기본적으로
- batch: 16, 32 / learning rate: 5e-5, 3e-5, 2e-5 / epoch: 2, 3, 4를 추천
- pre-training 단계에선 unlabeled data를 사용
- fine-tuning 단계에선 특정 task에 대해 label된 supervised learning을 진행

(a)는 두 개의 문장에 대한 분류
(b)는 하나의 문장에 대한 분류 task로 [CLS] 토큰이 분류문제에서 classification output으로 사용
(c)는 QA task로 [SEQ] 이후에서 start/end span을 찾음
(d)는 각 토큰에 대한 tagging을 하는 작업으로 각 토큰에 대해 분류하는 task를 진행
7. Experiments
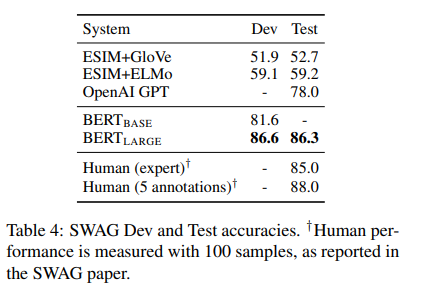
- 모든 경우에서 BERT(LARGE)가 SOTA 달성
- OpenAI GPT와 BERT(LARGE)는 attention masking을 제외하고 model architecture가 유사하지만 BERT(LARGE)가 좋은 성능을 보여줌
- BERT(BASE)보다 BERT(LARGE)가 좋은 성능을 보여줌



8. Conclusion
BERT 요약
1. unidirectional이 아닌 bidirectional
2. masked language model과 next sentence prediction task를 이용한 pre-training
3. 대규모 데이터셋을 통한 pre-training과 task-specific한 데이터셋에 대해 fine-tuning
'Python > 논문' 카테고리의 다른 글
| Attention Is All You Need (Transformer) (0) | 2024.07.16 |
|---|---|
| Effective Approaches to Attention-based Neural Machine Translation (0) | 2024.07.04 |